Kanoniczny adres URL (Canonical)
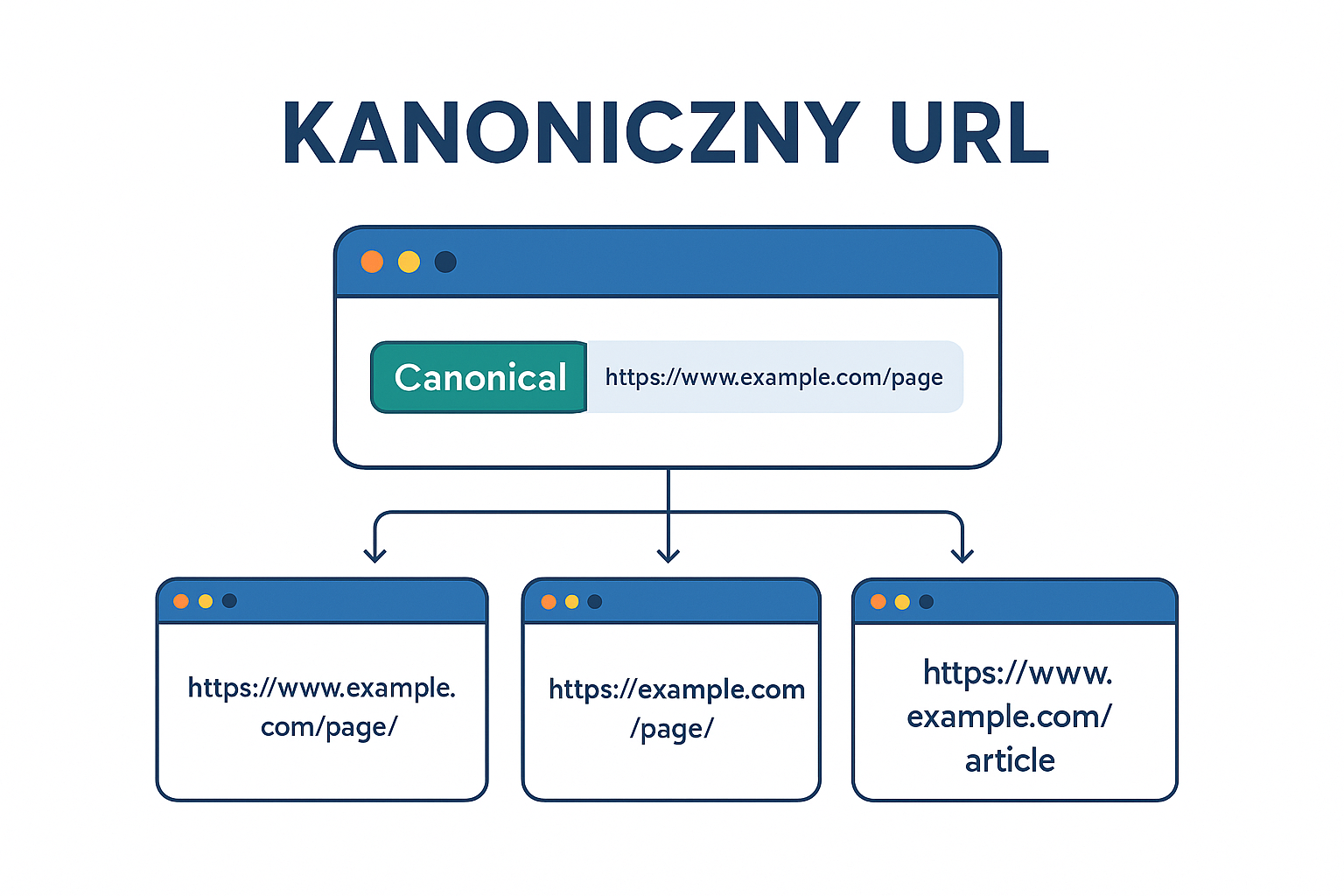
Co to jest kanoniczny adres URL?
Kanoniczny adres URL (ang. canonical URL) to specjalny znacznik w kodzie strony internetowej, który informuje wyszukiwarki, która wersja danej strony powinna być uznana za oryginalną i nadrzędną, gdy w internecie istnieje kilka zbliżonych lub identycznych wersji tej samej treści. Jest to kluczowy element w procesie optymalizacji SEO, szczególnie dla dużych serwisów, sklepów internetowych oraz portali z dynamicznie generowanymi adresami.
W praktyce chodzi o to, by uniknąć tzw. duplikacji treści (ang. duplicate content), czyli sytuacji, w której ta sama treść występuje pod różnymi adresami URL. W takich przypadkach Google i inne wyszukiwarki nie wiedzą, który adres powinien być traktowany jako główny, co może prowadzić do rozproszenia autorytetu strony, problemów z indeksowaniem oraz spadków pozycji w wynikach wyszukiwania.
Przykład: Twoja strona produktowa może być dostępna pod kilkoma adresami:
- https://example.com/produkt/fotel
- https://example.com/produkt/fotel?utm_source=newsletter
- https://example.com/produkt/fotel?sort=price
Jak działa znacznik rel="canonical"?
Znacznik rel="canonical" umieszczany jest w sekcji dokumentu HTML. Wskazuje on wyszukiwarce preferowaną wersję strony:
< link rel="canonical" href="https://example.com/produkt/fotel" />
Kiedy robot Google odwiedza daną stronę i widzi ten tag, traktuje wskazany adres jako kanoniczny – czyli ten, który powinien zostać zindeksowany i prezentowany w wynikach wyszukiwania. Pozostałe wersje strony mogą być zindeksowane, ale nie będą wyświetlane jako główny wynik.
Kiedy należy stosować adresy kanoniczne?
W praktyce istnieje wiele sytuacji, w których należy wdrożyć znacznik rel="canonical". Najczęstsze przypadki to:
- Strony z parametrami URL (np. sortowanie, filtrowanie, tagi UTM)
- Wersje stron dostępne przez różne ścieżki lub aliasy
- Wersje językowe bez użycia hreflang
- Strony powielające treść, np. w kategoriach produktów
- Strony AMP (Accelerated Mobile Pages)
Stosowanie adresów kanonicznych nie tylko ułatwia życie robotom wyszukiwarek, ale także pozwala właścicielowi witryny kontrolować, która wersja treści będzie preferowana w Google – bez potrzeby stosowania przekierowań.
Dlaczego stosowanie adresów kanonicznych jest ważne dla SEO?
Poprawne wykorzystanie kanonicznych adresów URL wpływa na kilka kluczowych aspektów widoczności w wyszukiwarkach:
- Redukcja duplikacji treści – Google może obniżać ranking stron, które powielają treści lub niepotrzebnie dublują strukturę URL.
- Konsolidacja sygnałów rankingowych – linki zewnętrzne, autorytet domeny i inne czynniki SEO są przypisywane do jednej, wybranej wersji strony.
- Efektywniejsza indeksacja – wyszukiwarki nie muszą indeksować wielu kopii tej samej treści, co oszczędza zasoby tzw. crawl budgetu.
Dzięki temu strona nie tylko unika problemów technicznych, ale także może zyskać wyższe pozycje w Google poprzez spójne i jednoznaczne sygnały SEO.
Jak prawidłowo wdrożyć znacznik canonical?
Implementacja tagu rel="canonical" może przebiegać na kilka sposobów, w zależności od struktury strony, technologii oraz potrzeb SEO. Najczęściej stosowane metody:
- Wstawienie w kodzie HTML: Dodanie tagu w sekcji
każdego dokumentu HTML. To najprostszy i najbardziej standardowy sposób. - Przez nagłówki HTTP: Przydatne np. przy plikach PDF – można dodać nagłówek
Link:; rel="canonical" - Poprzez CMS lub framework: W systemach takich jak WordPress, Shopify, Laravel – można używać dedykowanych wtyczek lub helperów do automatycznego generowania tagów canonical.
Uwaga: Canonical musi być dokładny – nawet mała różnica (np. slash na końcu, parametr, http vs https) traktowana jest jako inny adres. Warto upewnić się, że wskazywany URL jest rzeczywiście dostępny i nie prowadzi do błędu 404.
Canonical w sitemap.xml – czy to ma sens?
Chociaż mapa strony (sitemap.xml) nie zawiera bezpośrednio tagów rel="canonical", warto pamiętać, że **tylko kanoniczne adresy powinny być tam uwzględnione**. Oznacza to, że jeśli strona ma kilka wersji URL, tylko ta zdefiniowana jako kanoniczna powinna znaleźć się w sitemapie.
To zwiększa spójność struktury całej witryny i pomaga robotom Google w prawidłowej indeksacji oraz rozpoznaniu, które strony są rzeczywiście wartościowe.
Praktyczne zastosowanie canonical – przykłady z życia
Wdrożenie znacznika rel="canonical" powinno być oparte na rzeczywistych scenariuszach użytkowania, które często występują w sklepach internetowych, blogach czy portalach treściowych. Poniżej przedstawiam kilka typowych sytuacji, gdzie adres kanoniczny ma kluczowe znaczenie:
1. Sklep internetowy z filtrowaniem i sortowaniem
W sklepach e-commerce użytkownicy mogą sortować produkty według ceny, popularności, dostępności czy filtrów. Każda taka akcja generuje nowy URL z parametrami:
https://sklep.pl/buty?kolor=czarne&sort=price_asc
Jednak pod względem treści strona jest bardzo zbliżona do bazowego adresu kategorii:
https://sklep.pl/buty
Dlatego w takich przypadkach wszystkie strony z parametrami powinny mieć ustawiony adres kanoniczny wskazujący na główną wersję kategorii. To pozwala uniknąć setek powielonych podstron z punktu widzenia Google.
2. Wersje językowe i regionalne bez hreflang
Czasem strona dostępna jest w kilku wersjach językowych, np.:
- https://example.com/pl/produkt
- https://example.com/en/produkt
Jeśli nie korzystasz z atrybutów hreflang, możesz wykorzystać tagi canonical do wskazania jednej wersji jako nadrzędnej – np. najczęściej odwiedzanej lub z największym ruchem.
3. Duplikaty treści w różnych sekcjach portalu
Popularnym błędem w dużych serwisach jest publikacja tej samej treści w kilku kategoriach lub tagach. Jeśli ten sam artykuł dostępny jest pod trzema adresami – każdy z innej kategorii – należy wskazać jeden z nich jako kanoniczny. Dzięki temu unikasz kar za duplicate content i poprawiasz autorytet właściwej wersji.
4. Strony AMP a wersje klasyczne
Google zaleca, aby strona AMP (Accelerated Mobile Page) posiadała link rel="canonical" wskazujący na wersję desktopową. W przeciwnym razie może dojść do rozdzielenia autorytetu strony między dwie wersje lub błędów indeksacji.
Najczęstsze błędy związane z kanonicznymi adresami URL
Nawet dobrze zaprojektowane wdrożenie znacznika rel="canonical" może zawierać błędy, które osłabiają jego skuteczność. Oto lista najczęstszych problemów:
- Wskazanie nieistniejącego adresu – canonical prowadzi do strony 404 lub przekierowania, co uniemożliwia poprawną indeksację.
- Rozbieżność między adresem w przeglądarce a canonical – np. użytkownik widzi
https://example.com/sklep, a wrel="canonical"wpisanohttp://example.com/sklep. Taka niespójność może wprowadzać w błąd roboty indeksujące. - Kanoniczne pętle – strona A wskazuje jako canonical stronę B, a strona B z kolei wskazuje stronę A. Taka pętla powoduje ignorowanie tagu.
- Wieloznaczność – kilka canonical na jednej stronie – zgodnie ze specyfikacją w kodzie HTML może wystąpić tylko jeden tag
rel="canonical". Więcej niż jeden powoduje, że żaden nie zostaje wzięty pod uwagę. - Brak spójności z przekierowaniami – canonical powinien być zgodny z logiką przekierowań (np. 301 z www na bez www → canonical też bez www).
Czy canonical zastępuje redirect 301? Różnice i zastosowanie
Nie – rel="canonical nie zastępuje przekierowania 301, chociaż w wielu przypadkach może wydawać się podobny w skutkach.
Redirect 301:
- fizycznie przenosi użytkownika i robota z jednego adresu na drugi,
- jest twardym sygnałem zmiany adresu,
- przekazuje cały autorytet i historię strony.
Canonical:
- jest tylko sugestią dla wyszukiwarki,
- nie zmienia zachowania użytkownika (strona się nie przekierowuje),
- pomaga przy zarządzaniu duplikacją, bez zmiany struktury serwisu.
Wniosek: jeśli strona A powinna zniknąć i zostać zastąpiona stroną B – stosujemy redirect 301. Jeśli strona A może istnieć, ale nie powinna być indeksowana, bo jej treść jest wtórna – stosujemy rel="canonical".
Narzędzia do sprawdzania adresów kanonicznych
Weryfikacja działania canonical to ważny element audytu SEO. Najlepsze narzędzia do sprawdzania i monitorowania:
- Google Search Console – pokazuje, który URL Google uznaje za kanoniczny (zakładka „Pokrycie” lub „Inspekcja URL”).
- Screaming Frog – skanuje stronę i pozwala sprawdzić tagi canonical dla każdej podstrony.
- Ahrefs / SEMrush / Sitebulb – narzędzia do audytów SEO z raportami o błędach canonical.
- Rozszerzenia przeglądarki – np. „Ayima Redirect Path”, „SEO Meta in 1 Click”.
Regularne monitorowanie adresów kanonicznych jest kluczowe, zwłaszcza po wdrożeniach, migracjach lub zmianach struktury URL.
Podsumowanie – jak zarządzać adresami kanonicznymi?
Adresy kanoniczne to jedno z najbardziej niedocenianych, a zarazem najważniejszych narzędzi SEO technicznego. Ich poprawne stosowanie przekłada się na lepszą indeksację, eliminację duplikatów i efektywne wykorzystanie crawl budgetu.
Checklist wdrożeniowy:
- Każda strona powinna mieć
rel="canonical"– nawet jeśli wskazuje sama na siebie. - Adres canonical musi prowadzić do działającej, indeksowalnej strony (kod 200).
- Wszystkie duplikaty muszą wskazywać jeden, wspólny URL kanoniczny.
- Canonical powinien być spójny z sitemap.xml i strukturą przekierowań.
- Nie należy stosować wielu tagów canonical na jednej stronie.
Rozsądne podejście do adresów kanonicznych pozwala zachować kontrolę nad indeksacją i kierować ruchem oraz autorytetem strony tam, gdzie to naprawdę ma znaczenie.
8 lat doświadczenia
klienci z całego świata

Restauracja Tymff,
Właściciel